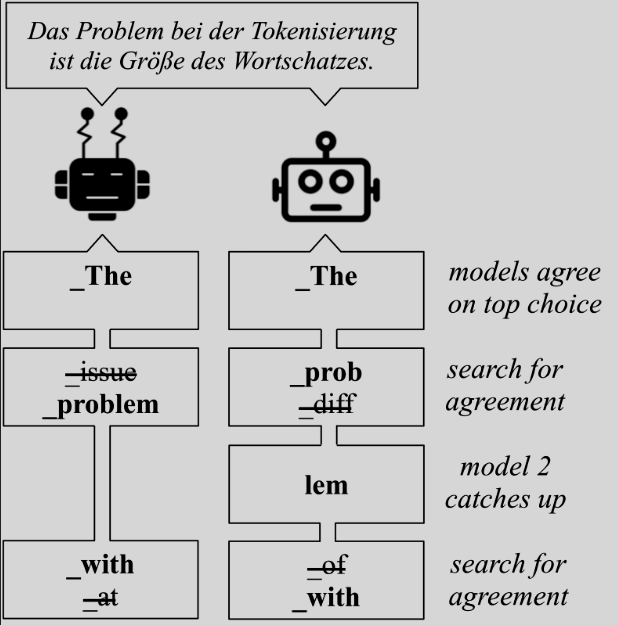
About me
I'm a final year PhD student at Johns Hopkins University. For the past few years I've been working with Matt Post and Philipp Koehn. My research has focused on the nitty-gritty problems (read: data improvements) that oft get overlooked, targeting improvement in machine translation. More broadly, I'm interested in multilinguality in generative models, with experience in sequence to sequence modeling, corpus creation, and data augmentation.
Projects
-
LIDIRL
A series of robust language identification models that improve performance on the long tail of errors from noisy web text.
This website is derived from a template you can find here.